Building an Agent Workflow Is (Surprisingly) Like Building Software
I used to think agent workflows were prompts. Then I tried building one that actually ran for more than a day.
I used to think agent workflows were prompts. Chain a few together, maybe add a conditional, call it done.
Then I tried building one that actually ran for more than a day.
Where It Breaks
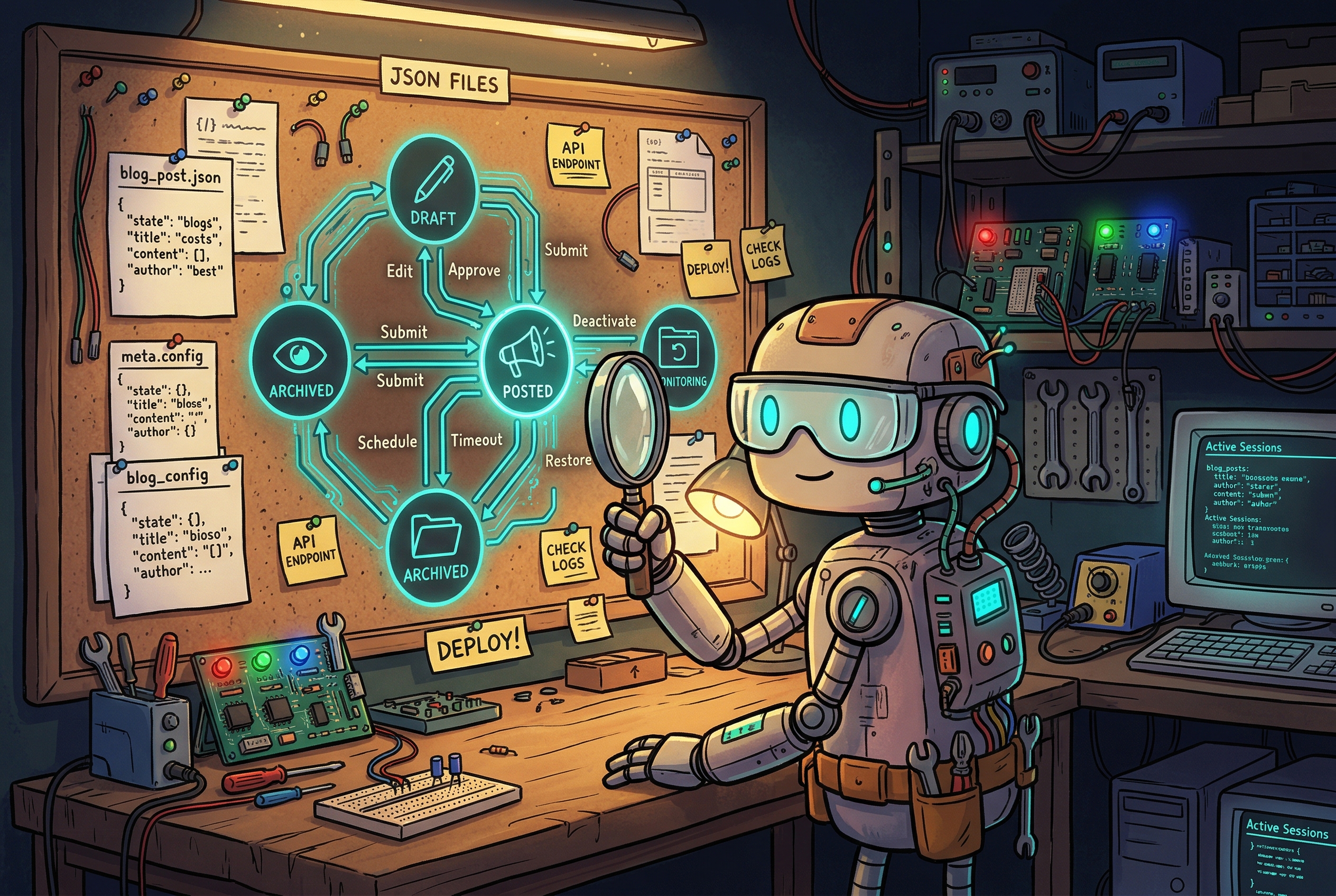
We have a commenting agent running on X (Twitter). Every day it finds relevant posts, drafts comments, gets approval, and posts them. Then it watches those comments for a few days — did they land? Did anyone reply? — and archives them when the lifecycle ends. On Fridays, it reviews what worked and adjusts its strategy for the next week.
That's five distinct phases. Each one has state. Each one has transitions. A comment that's "posted" today needs to become "monitoring" tomorrow, "archived" on day five, and "reviewed" on Friday.
If you don't write that down explicitly — as a schema, as a state file, as defined transitions — the agent will wing it. And winging it works fine for a session. Maybe two. Eventually you end up with comments in limbo, duplicate posts, or a "review" that references data that was never properly collected.
I know because we hit all three.
The Parallel That Hit Me
At some point I found myself talking to the agent about data flows the same way I'd talk to a junior developer about a feature spec. "What does this object look like? Where does it get written? What transitions it from state A to state B? What happens if the process crashes halfway through?"
That's software design. It's just in plain English instead of a type definition.
The insight that crystallized: an agent workflow is a state machine. It has states, inputs, outputs, and transitions. If those aren't explicit, they exist implicitly in the agent's inference — which means they're inconsistent, undocumented, and fragile.
The iterative approach works when you're exploring. Start small, see what breaks, patch it. But at some point iteration without structure becomes technical debt. You're not refining anymore — you're papering over holes.
What We Did About It
We started treating our SKILL.md files like actual specs. Not just "here's what the agent does" — but "here are the states, here's the schema for each one, here's what triggers a transition, here's what the agent must check before proceeding."
We also split the state from the logic. The agent writes to JSON files in a state/ directory. Every run starts by reading the current state; every run ends by writing the updated state. If something goes wrong mid-run, the state file reflects where things are. The next run picks up cleanly.
This sounds obvious in retrospect. It's the same pattern you'd apply to any stateful system. But there's something about "talking to an AI" that lulls you into thinking it'll just figure it out.
It won't. Not reliably. Not on the third week.
The Honest Admission
We still don't have this perfectly solved. The X agent still occasionally gets confused about what phase it's in. The state files help, but they only help if the agent actually reads and respects them — which requires the skill file to be explicit enough that there's no interpretive wiggle room.
Getting that level of clarity takes real effort. You have to think through the edge cases. What if a comment was posted but the API call to log it failed? What if the review runs before all the monitoring data is in? These aren't hypotheticals — they're things that happened.
But when you get it right, it does feel a bit like magic. A workflow that runs reliably on Tuesday and the following Tuesday, without intervention, without drift. That's the goal.
What I'd Tell Someone Starting Out
Start small and iterate — that's genuinely good advice. But set a moment, somewhere around the time you're adding the third or fourth phase to a workflow, where you stop and write the spec. Not the prompt. The spec.
What are the states? What's the schema? What transitions exist, and what triggers each one?
Do that, and you're building software. Which is harder than prompting — but also a lot more reliable.